发表时间:2020-04-06
如今,推荐系统已经在各行各业中有所应用,在知乎,推荐系统更是一项核心功能。
据了解,目前知乎的推荐系统主要分为两部分:一部分是首页信息流的个性化推荐;另一部分是在各种用户场景,比如问题路由、相关推荐等等功能上的推荐。
在这些场景下面,知乎用到的技术并不是完全一样的,所采用的技术架构也并不相同,张瑞告诉记者:主要还是根据用户场景来决定使用什么样的架构和技术。
在首页的个性化推荐里,主要采用的技术包括:对图文内容、视频内容的基本的识别和画像,对用户的画像,以及图文内容和视频内容里面的实体识别以及关联,张瑞表示这些都是基础的组件;而上层在召回排序环节则大量的采用了 DNN,也就是深度神经网络技术。
由于平台的发展,早先单纯以图文为主的交流方式已经不足以让用户满足,于是知乎平台上也出现了不少视频、音频的内容,但是文字仍然占据了大量的比重,这对于知乎的推荐系统来说是个好事儿。
为什么这么说呢?张瑞解释道,图文推荐系统和其他推荐系统的区别在于:目前的 AI 算法技术对图文内容的理解会比视频和音频多媒体更加深入。而且对于绝大部分公司来说,在图文推荐系统中对图文内容本身做深入理解,从成本上也是可接受的。这种理解不只是从用户的交互入手,或者把一个图文内容看成单个、原子的 item,而是更深入的去了解某篇图文到底讲的是什么、它的质量是什么样子等等一系列的信息。所以其实相对于商品推荐、视频推荐等等领域,图文推荐会有更多的信息可以使用。
“当然现在业界在做图文推荐系统的时候,也会使用到这些信息。”张瑞说:“大家在这一领域的竞争还是很激烈的。这个激烈就在于:每家公司对图文内容的刻画、选择的维度都是不一样的,能做到的深度也是不一样的,而这个维度和深度本身就决定了图文推荐能做到用户的体验的上限有多少。”
为了提升用户体验的上限,知乎推荐系统也经历了升级改造。
张瑞告诉我们,知乎最初的推荐系统版本非常简单,仅仅是根据用户的关注行为进行推荐,比如有新的话题出现,用户一旦关注了就推荐给 TA 相关的内容,不关注就不推荐。此外,推荐的排序也是非常简单的,就是依靠时间流,即使后来引入了 EdgeRank 之类的简单的算法,做到的也仅仅是时间、文本内容质量等相关的权重的一个简单的信息加权。
随着新用户的进入,研发团队发现:在 Feed 流推荐场景下,用户都是越来越“懒”的,大部分用户希望不进行繁琐的操作,就能得到非常好的推荐结果。于是,推荐系统团队针对性的进行了一些优化,比如:在召回环节,引入更多根据用户的行为来召回内容的方式;在排序环节,把用户的各种行为,以及内容的各种细致刻画都引入进来,通过 DNN 神经网络进行排序,无论是老用户也好,新用户也好,整体上去优化他们的体验。
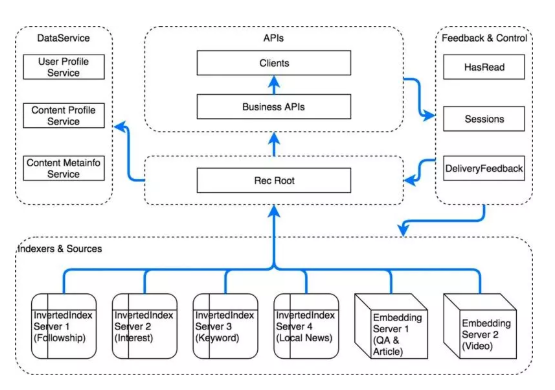
知乎多召回源融合的推荐结果生成框架
张瑞说:“从效果来看,新的系统上线了之后,对比最初的版本,分发量等等指标基本上都增长了至少三倍。”
多目标学习的推荐系统
知乎 CTO 李大海曾经在去年的一次演讲中提到了“多目标学习”的推荐系统,据了解这也是知乎优化推荐系统的一个方向。那么这个“多目标学习”该如何解释呢?
张瑞告诉我们,一般来说在搜索和推荐等信息检索场景下,最基础的一个目标就是用户的 CTR,即用户看见了一篇内容之后会不会去点击阅读。但其实用户在产品上的行为是多种多样的。尤其在知乎,用户可以对某个内容进行点赞,可以收藏这个内容,可以把它分享出去,甚至某个问题如果他觉得比较符合他的兴趣,想去回答,也可以进行一些创作。
虽然可以对用户的 CTR 进行单个目标的优化,但是这样的做法也会带来的负面影响:靠用户点击这个行为推荐出来的内容并不一定是用户非常满意的内容,比如有人可能看到一些热门的内容就会去点击,或者看到一些阅读门槛低的内容,像一些引发讨论的热点事件、社会新闻,或者是一些轻松娱乐的内容,用户也会点击。这样造成的后果就是:CTR 的指标非常高,但是用户接收到的推荐结果并不是他们最满意的。
后来,知乎的产品研发团队发现:用户的每种行为代表在一定程度上都代表了某个内容是否能满足他不同层面的需求。比如说点击,代表着用户在这个场景下,想要看这个内容;赞同,代表用户认为这个内容其实写的很不错的;收藏,代表这个内容对用户特别有用,要把它收藏起来,要仔细的再去看一看;分享,代表用户希望其他的人也能看到这个内容。
而单目标 CTR 优化到了一个比较高的点之后,用户的阅读量虽然上去了,但是其他的各种行为(收藏、点赞、分享等等)是下降的。这个下降代表着:用户接收到太多的东西是他认为不实用的。
于是,推荐系统团队陷入了思考:能不能预估用户在其他行为上的概率?这些概率实际上就是模型要学习的目标,多种目标综合起来,包括阅读、点赞、收藏、分享等等一系列的行为,就能综合到一个模型里面进行学习,这就是推荐系统的多目标学习。
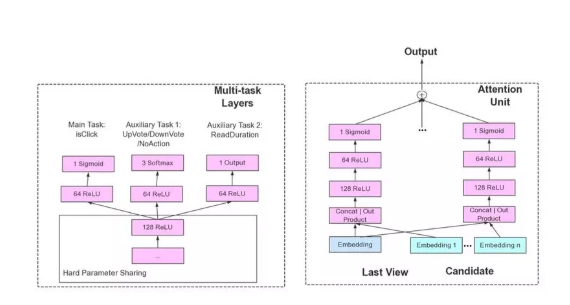
"多目标"预估模型
与所有的系统类似,知乎的多目标推荐系统最初也是一个比较简单的版本,仅仅是给各个目标学习一个模型。这种情况下,模型本身的训练和在线预测的负担就会非常严重,每一个模型的训练和预测都要耗费同样的资源,这样对于工程资源压力是非常大的。这些模型之间还有互相的交叉、验证;每个模型还需要评估,离线评估一遍,在线评估一遍,之后再合并... 林林总总的行为加起来,对研发资源造成的负担是非常大的。
所以,在多目标推荐系统的第一版做出来之后,团队就在考虑:能不能使用模型之间共享一些参数的方式,或者共享模型本身以及训练流程的方式,来减少在训练上的负担,以及它在工程成本、研发成本上的负担?
以此想法为基础,团队做出了一个能够在底层共享相关参数,在顶层根据各种模型、目标本身特点而学习的特有的神经网络架构,张瑞说,这套架构中参考了很多现有的多目标学习的研究进展。
虽然解决了一部分问题,但是把多个模型融合在一起,通过一个模型去学习一个目标的方式仍然存在问题。
首先,目标之间的相关性决定了这个模型学习的上限能有多少。比如:如果一个模型中点赞和点击是完全耦合的,那么这个模型在学习点赞的过程中,也就学习了点击。但是对用户来讲,它的意义是不一样的,这并不是一个完全耦合的系统。
在这个学习任务下,如果去共享底层网络参数的话,可能会造成底层的每个目标都能学习一点,但是每个目标学习的都不够充分,这是多目标学习系统实现的一个难点。为了解决这个问题,研发团队参考了 Google 发表的一篇论文,叫做 Multi-gate Mixture-of-Experts,简称 MMOE。
MMOE 的核心思想是:把底层的网络划分成一些专用的模块,虽然底层参数是共享的,但是通过目标和网络参数之间的一个 gate(门)来学习,让每部分网络充分学习到对每个目标的贡献最大的一组参数结构,通过这种方式来保证,底层网络参数共享的时候,不会出现目标之间相互抵消的作用。
张瑞告诉我们,经过尝试之后,交互层面的预估子任务的 AUC 值得到了至少千分之二的提升,在模型的主任务也就是预测阅读的任务中,AUC 也没有下降。上线之后,取得的效果也是非常正向的。
张瑞还跟我们同步了一些数据。从数据来看,在引入多目标学习之前,知乎的预测模型已经做到了非常高的准确率,在引入多目标学习之后,或多或少都会对阅读行为有一定的负向作用:多目标学习在上线以来,阅读行为下降了 2% 左右,但是用户的其他行为(比如点赞、收藏、评论、分享等),分别提高了 50%~100%。
如果看最直接关系到用户体验的数据,也就是用户的留存率,上线多目标学习之后,知乎的整体用户留存率大概提升了 5% 左右。“对于任何一个推荐系统来说,整体的用户留存率能提升 5% 都是非常高的收益。”张瑞补充道。
至于用户反馈,张瑞告诉我们,现在知乎有一些固定的渠道方便用户提供反馈。他告诉我们:“在引入多目标学习之前,我们接到的最多的反馈就是用户觉得在 Feed 流里,内容越来越浅显。这些反馈主要来自于知乎的重度用户和一些比较老的用户,他们对知乎的期望都是非常高的,希望知乎能够把一些特别有用的知识带给他们。之前,机器的优化阅读会带来一些反向作用,有用户觉得知乎推荐的内容虽然都特别抓人眼球,但实际的用处并没有那么大。在新的推荐系统上线之后,很多人表示 Feed 流里面的内容质量变高了,用户沉浸式的体验感变得更深了。”
引入多目标学习的推荐系统在知乎已经收获了不少的正面效果,但是张瑞表示,团队目前遇到的一个令人困扰的问题是:多个目标中,到底以什么样的方式去对目标进行权衡和融合,才能得到用户收益和平台收益的最大化?
打个比方,用户其实在 Feed 流里面消费内容的时候,他期望的并不是非常单一的场景,系统提供一些供消遣而浅显的内容,阅读量会上涨,但是用户会觉得体验不好;但如果推荐的全是一些收藏率特别高的内容,对于用户来讲,虽然这类内容非常有用,但阅读起来会很累。
张瑞说:“对于平台来讲,我们最关注的是用户在 Feed 流的场景下面的体验如何。这直接关系到我们用户的留存和用户的活跃。”
所以现在知乎在尝试一些解决方案,包括对用户进行分群,看某个群体的用户最在意的是什么样的内容。但这是一个通过产品经理,或者通过人的观察来确定的事情,比如说某些领域的重度用户会特别在意推荐的内容对他们有没有用;一些轻度的用户,他们来到知乎的主要的目的是为了轻量阅读,一些易于消化的内容对他们更友好。
对用户分群之后,就可以动态调整每个目标的权重,给出一个最终的排序。这对于推荐系统当然是有收益的,但是张瑞认为在现在还没有一个非常完善的方法来判断,什么样的群体、什么样的目标,他们之间以什么样的比例去进行融合,从而给最终全局一个最好的收益。
现在业界的各种推荐系统的方法,大家都会去预测 CTR(点击率)、预测 CVR(转化率),预测各种各样行为的概率,但是很少有公司去做预测用户的留存。这也是整个推荐行业,或者说推荐技术圈面临的一个挑战:所有的这些行为概率,都是用户体验的一个方面,不能代表用户体验的整体最优,那么,用什么样的方式能够给用户的体验带来最大化的收益,仍然是业界目前面临的一项挑战。张瑞认为,通过多目标学习来间接的达到这个目标,间接的达到全局最优化,对于提升用户体验也许是一种解决方式。
未来规划
除了多目标学习,有两个方面的技术发展也是张瑞极其关注的,他认为,这两项技术对推荐系统也是很有帮助的。
首先是对于内容质量的判别。
知乎的场景主要是图文,所以开发人员也会更在意图文质量的判别。图文质量的判别包括细粒度特征,比如某个内容对于什么样的用户来说是好内容,对于什么样的用户来说不是。举例来说,一篇讲机器学习基本知识的内容,对于机器学习的入门初学者可能是非常好的内容,但是对于知乎上面的一些机器学习大牛就是一个并没有多少信息量的东西。
张瑞表示,怎么能够实现对内容质量,或者内容价值的细粒度的刻画是非常难的一件事,好在业界一直在技术上推进,现在取得了一些进展,包括 Google 最近发表的论文 BERT,它能够对文字内容进行不同于往常的 embedding 嵌入式表示。
其次是对于深度神经网络的解析。
现在的很多场景都用到了深度神经网络,但是张瑞告诉我们:对于深度神经网络来说,绝大多数的场景仍然是黑盒子,即使再往前进一步,不是绝对的一个黑盒子,起码也是一个灰盒子。
在中间的输入和输出之间到底有什么样的关联?哪个输入的因子能够对输出起到最重要的作用?这个作用能不能可量化的去评估?现在业内在这一领域的研究的成果并不是非常多,所以张瑞觉得,怎么去解析一个 DNN 的网络,实际上是对应到开发者能不能真正的去了解这个模型,能不能去准确的判定它是怎么工作的,以至于,能不能对下一步的工作提供指导,比如什么样的特征,或者什么样的网络构型能够产生更大的收益?
现在大部分情况下还是靠人的经验,一点点的去尝试,如果能够把 DNN 的解析给做好,在未来的各种迭代的效率,以及研发的效率可能就会出现一个质的飞跃。
深度神经网络解析对于推荐系统可能会更重要。张瑞强调道,现在有些研究是在针对推荐系统的可解释性,但是很多时候用户看到的推荐内容,实际上是不清楚为什么推给他,如果不清楚原因,有些用户就没有动力仔细的去看。比如在网上上买东西,电商平台推荐的商品根据用户性别甚至是消费级别进行推荐的,但是对用户来说,如果不给出一个解释理由的话,用户或许很难去想到这个东西到底跟自己有什么关联。
张瑞认为:“如果对于深度神经网络的解析,能够有一个比较大的进步,我们可以反向倒推出来,把哪些东西推给用户是最重要的,同时也就可以给这个用户解释,我为什么给你推这个东西,能够提高用户的筛选效率,并且提高用户的在整个推荐系统上的黏性和消费意愿。”
最后张瑞谈了谈对知乎推荐系统未来发展的规划与期待。
从用户的决策面来说,知乎推荐系统团队希望能够多样的提升用户和信息之间的匹配的准确性,尽量把更多的信息带给用户。可能需要通过上文提到的各种各样的方式去一点一点实现这个目标。
从平台方面来说,首页的推荐系统在知乎流量来源里面占有非常大的比重,同时也支撑着知乎各个业务的发展,所以,张瑞希望打造出一套非常灵活的系统,能够根据业务当前的需求,或者公司目前的运营状态,把流量导去对平台、公司和用户有益的地方,最终实现流量分配之后,对流量使用的价值进行评估的一种机制。


 工作时间
工作时间
